 CS470/570 Artificial Intelligence
CS470/570 Artificial Intelligence
Program #2: RoadWarrior meets Google Maps
(a.k.a., Searching like a homo sapien)
Overview:
Now that we are well on the way to understanding the concept of “state space search” with our primitive Boggle-bashing, it’s time to have a deeper look at searching to better understand what it is we were doing in Fred Flintstone mode, how this fits into the full range of options possible, and what the practical differences there are between some of the main searching options.
To explore these questions, let's switch from Boggle to a more classic search problem: route-finding on complex maps. This is pretty much exactly the problem that Google Maps solves every time you ask for directions to someplace, and you can be sure that they have lots of data and some good AI going into providing you with an answer...because they are increasingly competing with others (e.g. Apple maps) for your patronage! For our exploration, we'll keep it simple: we just want to find a route from some some starting point to some ending point, knowing only what the road network looks like. Some of the real-life questions we might want model include:
- How can I get from point A to point B? For the common "person driving in the city scenario", we can add the obvious addendum "...as efficiently/quickly as possible".
- What are all the ways to get from point A to point B? The scenario here might be that there has just been a bank heist downtown, the police know the bad guys are heading for the interstate on-ramp (point B), and they need to consider all paths. Or, less dramatically: city engineers are modeling traffic flows and need to consider all routes. This one also most closely resembles our Boggle problem, where we wanted to find all possible solutions in the search space.
- What is the closest of several possible options? So maybe you need a hospital, you know there are three in the area, and need to find the route to the "best" one.
We'll explore at least a couple of these scenarios in our toy map world, while looking at how different possible searching algorithms would handle each. There are, of course, many many other domains in which we might explore the concept of "large state space search" that lies at the heart of much of AI: chess, moving a character through a maze, planning the best possible sequence of actions for your robot, etc. etc.
One huge advantage of the network navigaton domain is that it's naturally nice to visualize the search: unlike Boggle, the search space is just the map...so you can literally watch your search progress to understand how each algorithm really works. Actually *getting such a visualization up and running* is a whole different story of course! Graphical layout and programming is particularly vexing and challenging to program. Fortunately, your intrepid prof has jumped in to create some useful tools here, leaving you to focus on the search algorithms that we're really interested in! Some details are given further down. Note that there is nothing that REQUIRES you to use these tools...but you'd be silly not to use them to really get your mind around what's going on!
The Assignment:
 Our aim in this programming exercise is to explore the implications of different search algorithms and heuristics in a nice, easily-vizualized route-finding domain. Specifically, your challenge is to implement a general search engine program capable of doing DFS, BFS, Best-first, and A*. As evident from book and lecture, this is really a single base algorithm that you can manipulate to produce the various search behaviors. The idea is that your program runs repeatedly, exploring a given map using each of these algorithms in turn. Of course, if everything is working correctly, all of the searches will find a desired route (assuming one exists)...but you will see that they have *dramatically* different search behaviors. We've discussed some of the pros/cons of these algorithms in lecture (completeness, time/space complexity, and optimality); the aim here will be to see what this REALLY MEANS in a hand-on scenario. Your program will print out the statistics for each search run as it completes that search. For the A* search, I will ask you to explore one informed heuristic, with top score requiring the exploration of two or more.
Our aim in this programming exercise is to explore the implications of different search algorithms and heuristics in a nice, easily-vizualized route-finding domain. Specifically, your challenge is to implement a general search engine program capable of doing DFS, BFS, Best-first, and A*. As evident from book and lecture, this is really a single base algorithm that you can manipulate to produce the various search behaviors. The idea is that your program runs repeatedly, exploring a given map using each of these algorithms in turn. Of course, if everything is working correctly, all of the searches will find a desired route (assuming one exists)...but you will see that they have *dramatically* different search behaviors. We've discussed some of the pros/cons of these algorithms in lecture (completeness, time/space complexity, and optimality); the aim here will be to see what this REALLY MEANS in a hand-on scenario. Your program will print out the statistics for each search run as it completes that search. For the A* search, I will ask you to explore one informed heuristic, with top score requiring the exploration of two or more.
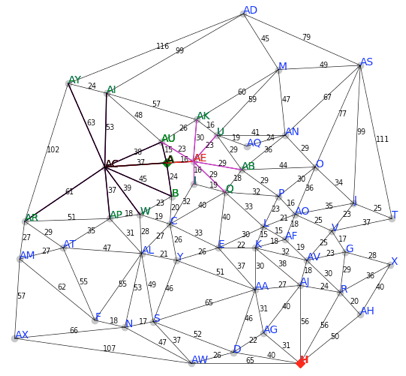
The search spaces for this problem will be maps, such as the one visualized on the right. Specifically, you will need to be able to load a "map" from a simple text file with very simple format, with each line of the file describing one edge in the graph:
(node1, node2, edgevalue, [x1,y1],[x2,y2])
To do the search, you technically only need the first three of these; the x-y positions of the two nodes are only needed if you want to actually lay out/visualize the search graphically. For instance, here is the map file for the map shown on the right. The map on the right is actually a snapshot of the GraphViz tool I made in action: start and goal have been marked, and a search has been started and has explored several nodes.
Important note: We want our maps to simulate real life! Look *carefully* at the map on the right and you will notice that the distances on the edges are NOT just straight-line-distance (SLD) between the nodes...reflecting the fact that in real life, the length of a road between two places is almost always longer than a "way the crow flies" SLD between the places! In other words, you can assume the following constraint: maps will always show distances between nodes, and these distances are *vagely* representative of the physical distance between them, but will often be longer (never shorter) than a calculated straight-line-distance between node coordinates.
Programming: What functionality you need to provide
Your task is to create a software tool for searching maps. It should be able to:
- Be able to load a map from a mapfile of the format specified above.
- Be configurable to run one of four search types: breadth-first (BFS), depth-first (DFS), best-first (BEST), and heuristic search (A*)
- For a loaded map, be able to specify a START node, as well as one *or more* GOAL nodes.
- Once start/goal(s) are specified, it can run the search. Provide options to run X expansions (search steps)...or just run the whole thing till it finds a goal.
- Has a "verbose" parameter. When "verbose" is turned on, it prints between each step: the node it is exploring, the new nodes generated to explore, and the current OPEN (frontier) list. In addition, verbose mode makes it print out all of the nodes explored in a search when the search finished, *in the order they were explored*. This allows us to see exactly how a search functioned.
- Finally, to implement the A* search, you'll need to pass in a heuristic function, h(n), for it to use to evaluate new nodes generated. Fortunately, this is super easy in Python, which allows you to simply pass functions as parameters!
- Heuristic Function 1 (hSLD): At minimum, you'll need to develop a simple "Straight Line Distance (SLD)" heuristic function, that guesses how close a node is to a goal by calculating the distance from that node to the goal (if there are multiple goals, it returns the distance to the closest one).
- Heuristic Function 2 (hDir): When you think about it, hSLD is only useful if you literally have a map in front of you and can easily calculate distances between nodes and the goal. That works for computers (Google Maps)...but it's not a very good model for how humans actually navigate in the wild. Think about how you personally navigate (without a GPS!): you often have a good idea of the approximate *direction* the goal lies in...but that's about it. So as you are at an intersection deciding which road to follow next, you often follow the one that "seems to lead in the right direction". The function we'll call hDir works to simulate this: it should essentially compute some sort of directional heading between a node (where you are now) and the nearest goal, and then compare this to the heading computes to each possible child node. Obviously the child node that is "closest" in heading towards the goal should get the highest score. This function is technically optional, but will be required if you want a top score.
Required output: what to show on your sample runs.
For all searches done, your awesome searcher should report:
- Search type it's doing, and the name of the input file that map was taken from.
- The start node and the goal node(s) set for that search
- The number of expansions that were done, i.e., the total number of nodes searched to find the solution.
- What node the search ended at (hopefully a goal node!) and the path cost of the path it found.
- The actual path to the goal: start by noting the length of the path, then show the nodes in the path from start to finish
- Search Stats! Average and Maximum OPEN list size, Average and Maximum depth reached during the search, and average branching factor of nodes expanded.
For searches done with VERBOSE mode turned on, the following should also be shown:
- At each step: The node being expanded, the children nodes generated, and the OPEN list after adding those new nodes.
- After the search finishes, after showing the other stats above: a list showing the nodes expanded, *in the order they were expanded*, starting with the root.
Don't worry, we'll only turn on verbose mode for testing where we specify a small number of expansions to do, or for very small test maps!
Here are a couple of sample output files to show you what your solution should be producing:
Required details, pay attention!
As you can see from the specs above, your program needs to provide certain outputs...which will allow me to evaluate whether you have correctly implemented the targeted search functionality. In order for this to work out (i.e., for us all to produce easily comparable output for a given search on a given map), we need to all answer address certain "undefined" issues in the same way. Please observe the following rules in implementing your solution:
- You may use only "standard" Python data structures and packages! That means lists, tuples, dictionaries, etc. --- nothing that you need to "import". The only packages that you may import relate to some obvious utilities: you can use scipy.spatial if to do some things like computing distances between cartesian points, etc. Other useful utility functions could be used from "sys", "math", "numpy". And of course you can import that GraphViz and GraphMaker classes that I provide as tools. You get the picture: nothing fancy that you discovered while snooping around the internet. If you have a doubt, ask.
- For BFS and DFS, the algorithm specifies where in the OPEN list newly generated child nodes go...but does not specify *how those siblings should be ordered* amongst themselves. So for instance, if you had a node "A" you were exploring and found that it was connected to nodes (T, K, Z, B, N) you would want to add these to your OPEN list to explore next. But do you add (T,K,Z,B,N)?...or (Z,T,N,K,B)? The basic algorithm doesn't specify because it doesn't matter...so long as they are added. But of course, how you add them will change the order of nodes explored during your search! To make sure everybody's output for a given search is the same, we will specify that newly generated nodes for BFS and DFS are *ordered alphabetically*, i.e., so that siblings get explored in alphabetical order. Thus for the above example, you'd add (B,K,N,T,Z). This is super simple: in your "successors" function, you'd compute the legal next nodes...and then simply sort that list alphabetically before returning it.
- The OPEN list (frontier Q) is ordered from front to back, meaning that when you view the list, the NEXT node to be explored appears at the FRONT of the list (item[0]). So as you explore nodes, you will be plucking the next node to explore from the front. Again, this makes it easy to understand when people print out their OPEN list.
- If you are inserting a child node that already exists in OPEN list (already another path to it found earlier) you only keep one copy. For Best and A*, the algorithm is clear: you keep only the "better" of the two. For breadth/depth first, we will do the following for consistency: breadth-first, drop the new child (keep the existing node); for depth-first, keep the new child, drop existing.
- In verbose mode, where you print your OPEN list, data for each "node" shown in the list must show, *in the following order*, (nodelabel, node depth from root, g(n), h(n), f(n)). The latter float values should be formated to one or two decimals for compactness. See my sample outputs linked in this spec.
- For consistency across all our outputs, the following stats are recorded updated in the moment after a new node is pulled from the OPEN list for exploration: OPEN list stats, node depth stats. The branching factor stats are updated as soon as all possible siblings of a node are generated...but before any illegal (e.g. previously visited) nodes are pruned away.
- I have specified the required content of your "search stats" output below...but you also need to *closely match my format*. Not down to each space or blank line, but the order and format of presentation should closely match what I've shown in the sample runs. This will make it much more straightforward to evaluate your work!
Some comments on implementation:
- As usual, it's the clear thinking and planning that will get you over the finish line on this one. Do you REALLY understand state space search? If not, go back and review the Chapter 3! After all, the algorithm is right there in the book! All you have to do is implement each of the key functions within it...and of course, understand how those functions change to create the different search types.
- Obviously, good coding practices and nicely-factored software design will make this a fairly simple assignment to do. My solution has three classes: a Searcher class that creates search objects. You init them with a board file to load, the type of search you'd like, and a heuristic fn (if A*). Some methods include ways to run the search (optionally for X steps vs whole thing), way to set the start/goal nodes, and ways to print stats. Then I added a SearchNode object to represent the nodes, and a Stats object to attach to a Searcher to keep track of stats. Makes for clear, elegant code, rather than just an tangled list-manipulation fest! So now I just instantiate the search class, then I just tell that new object to "search", and later I can query it for results. Clean!
- The devil is in the details! The hardest function to implement correctly is the one INSERT function that inserts new siblings into the OPEN list. Be careful here: the OPEN list should at no point in the search contain the same node label twice. Your search may have found its way to a given node through multiple paths...but you will never keep more than one to explore next!
- Graph creation and visualization tools. You don't actually need to vizualize the map to create your search solution...but doing so can be VERY useful for helping you to understand how various search algorithms are working...not to mention for noticing little bugs in your searcher's behavior. A nice tool for easily making new maps for your to explore is also useful; doing so visually beats trying to do so by writing up the textual map files by hand! To help you learn better, I've made you graph visualizer and creator tools; you are free to use them as you like. Find these tools here.
Your write-up:
In addition to your code and solution print-outs, you'll
need to provide a nice write-up of your solution. Your write-up should be professionally
neat and must include:
- A brief description of your solution
approach/strategy. Introduce how you factored the problem (major classes and/or functions) and what each of them does. You don't
need to describe every little helper function, just walk us through an overview of how your code tackles the problem.
- Analyze your heuristic function(s) that you developed for the A* search. Are they admissible? Are they consistent? Define each concept, analyze whether each h(n) you did meets that bar. With this in mind, can you guarantee that you A* searches guarantee optimal routes? If not, can show me a map in which your functions do NOT find the optimal route?
- So what is the difference between the algorithms? In which situations does one work better than the others? Do some exploration to generate some data to answer these questions by creating at least two reasonably complex (>30 nodes) maps. Then do the following on each map, recording your stats every time:
- Select five different start-goal combinations, choosing them to be different from each other. Closer, farther, heavily connected, on the edge, in the middle. The idea is that you're trying to somehow get a spread of possible start-goal conditions.
- Now run each of the algos on the map, for each of the start-goal conditions. Record your stats for each run.
- Now, repeat (1) and (2), but with the following change: choose a start point...and then multiple goals. So no you have five conditions where you have multiple goals.
- Again, run all your algorithms/heuristics on each start-goals condition. Record your stats.
- Now analyze the data you generated. First show your raw data in one or two nice tables (one for each map analyzed). Then add some column/row statistics to compare, for each search type and start-goals combo the average of: goal path cost, goal path length, number of nodes explored, etc. What you are trying to do is to see if you can see some patterns. Does one type of search always do better? Or does it only tend to do better for certain situations (e.g., close-by goals vs distant goals). Or maybe things change when you have multiple goals vs. just one? If you did multiple A* heuristics, which worked better?
- Now let's bring this back to reality: describe a heuristic function that Google Maps might actually use to generate routes. What are the inputs? How does it calculate a score? Remember, this function gets called *every time* a new search node is generated! Discuss the compuational complexity of running your function...and speculate on ways that Google might make this manageable.
- Write up the results of your analysis, answering questions like the ones suggested above...and noting any other patterns you exposed with your exploration. Whatever you present as your conclusions, it must be supported by the data your produced!! Do NOT just dump a bunch of data...and then speculate freely without any reference to actual data!
To turn in:
A professional packet with the following items in exactly this order:
Part 1: Making basic progress
- Cover sheet: Name, course, assignment title, date
- Printout of your program doing some simple "building block" things:
- Create a super-simple SearchNode class that has at least two fields: label and value. For now the value is just the path cost (from start) to the node.
- Show your program loading in the 30-node sample file above.
- Show you program setting start node=U and end node=T. Accompany your console action with snapshot of the graphical map after this action, i.e., using the GraphViz tool.
- Ask your program to show your OPEN list to see that indeed node U is in it. Your showOpen() function should print tuples of (label, value) for your list.
- You asking it to generate the SUCCESSOR (children) for node 'U'. This should return a list of the children of 'U'; as we said above, these siblings should be in alpha order.
- You asking it to INSERT the list of children produced above into your OPEN list. Show three inserts: at the front, and the end, and "in order", meaning a priority list based on the node value so that the cheapest node appears first in the new OPEN list. The insert should show us the new OPEN list each time.
- Now let's make sure your INSERT handles duplicates properly: manually create new nodes for (K,500), (C,91) and (J,10). INSERT these into your OPEN list, showing the results.
- Show your hSLD heuritic function being called on these nodes: V, AC, and J.
- Your richly commented and professionally presented code (maybe be duplex printed).
Part 2: The whole enchilada
- Cover sheet: Name, course, assignment title, date
- Your write-up to the analysis questions above, neatly typed up, cleanly formatted. Make sure you clearly label each answers so that I know which question it is addressing.
- Printout of your program output running the 10-node and 30-node samples given above. For each one, run the first three expansion steps with VERBOSE mode on, to show development of your OPEN list. Then turn VERBOSE=off, and let the searches run to completion to show the final stats.
- Printouts of your program running the dynamically
assigned searches. Link will be activated here shortly before due date.
- Your richly commented and professionally presented code (may be be duplex printed).
ATTENTION: when you are showing runs of your searches, *you must clearly label the printouts*!! Especially: you should carefully state what input map you are running on! An excellent way to help me out here is to attach a small snapshot of the graphical layout of the map...makes it easy to see which map your are running! Extra cool is if you've asked the visualizer to paintPath the final goal path found by your search, so that it's showing in red on the map!